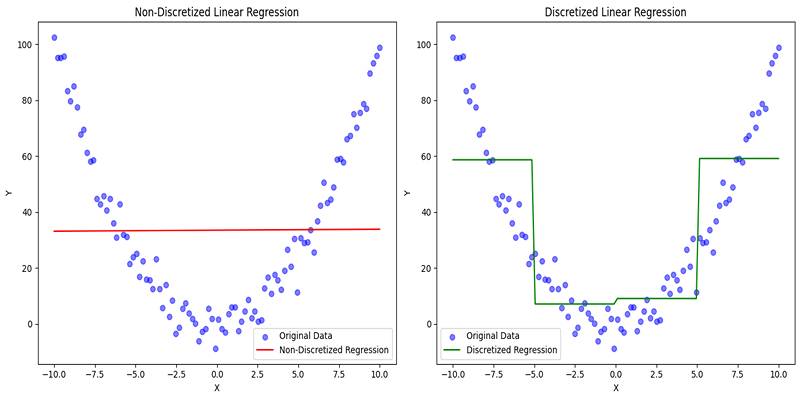
Discretization in machine learning plays a key role in making continuous data more manageable and easier to analyze. Many real-world datasets include numerical values that vary on a wide range of scales. These values are often too detailed for certain models or interpretations. Discretization offers a solution by converting these continuous values into distinct groups or intervals.
This guide explains discretization in-depth, covering its definition, various types, real-world applications, and the pros and cons associated with the technique. It is written in very simple wording to help both beginners and intermediate learners understand the concept fully.
What Is Discretization in Machine Learning?
In data processing, discretization is used to turn continuous numerical data into discrete groups or bins. Discretization turns numbers like 3.2, 7.5, or 10.8 into specific ranges like "Low," "Medium," or "High" instead of using them as raw numbers.
For example, consider a dataset with ages ranging from 0 to 100. Rather than feeding the raw ages into a model, these values can be grouped into:
- 0–18: Teen
- 19–35: Young Adult
- 36–60: Middle Aged
- 61–100: Senior
By converting continuous values into ranges, discretization helps simplify the data, especially when using machine learning models that perform better with categorical inputs.
Why Is Discretization Important in Machine Learning?
Discretization is especially valuable in specific modeling scenarios where raw continuous data may create noise or confusion. Several models, such as Naive Bayes classifiers and decision trees, often benefit from input features that are categorical rather than continuous.
There are multiple reasons why machine learning practitioners rely on discretization:
- Improves model interpretability: Discrete categories are easier for humans to understand.
- Simplifies data: Converts complex continuous data into manageable intervals.
- Reduces noise: Small variations in continuous data may not add value to predictions.
- Helps specific algorithms: Some models do not work well with continuous inputs.
- Handles outliers better: Discretization can reduce the influence of extreme values.
Types of Discretization Techniques
Discretization methods can be broadly divided into unsupervised and supervised approaches. The choice of method depends on the dataset, the type of model being used, and the objective of the analysis.
Unsupervised Discretization
Unsupervised techniques do not consider the target variable. These methods focus solely on the distribution of the input feature. There are two main unsupervised techniques:
Equal Width Binning
In equal-width binning, the entire range of values is divided into bins of equal size. For instance, a range of 0 to 100 divided into five bins would look like:
- Bin 1: 0–20
- Bin 2: 21–40
- Bin 3: 41–60
- Bin 4: 61–80
- Bin 5: 81–100
Advantages:
- Easy to implement
- Simple to understand
Disadvantages:
- It can result in an unequal distribution of data
- May create empty or overloaded bins
Equal Frequency Binning
Also known as quantile binning, this technique ensures that each bin contains roughly the same number of data points. For a dataset with 100 values and 4 bins, each bin would hold 25 values.
Advantages:
- Even the distribution of data across bins
- Effective for skewed datasets
Disadvantages:
- Unequal bin widths
- Similar values might fall into separate bins
Supervised Discretization
Supervised methods use the target variable (output label) to decide how to form the bins. These approaches aim to maximize the predictive power of the bins. One common method in this category is:
Decision Tree-Based Binning
This method uses a decision tree algorithm to split the continuous variable into categories. The tree automatically finds the best-cut points based on the target variable’s distribution.
Advantages:
- Produces bins optimized for the learning task
- Works well in classification problems
Disadvantages:
- It may overfit the data
- More computationally expensive
When Should Discretization Be Used?
Discretization is not always necessary, but it is highly useful in certain scenarios:
- Using categorical models such as Naive Bayes or logistic regression.
- When data contains outliers that need to be smoothed out.
- If features are highly detailed, causing noise in the learning process.
- For improved interpretability, especially in business or healthcare applications.
- During visualization, where grouped data is easier to plot and analyze.
Pros and Cons of Discretization
While discretization offers many benefits, it also comes with a few limitations.
Pros:
- Makes data easier to interpret
- Useful for specific machine learning models
- Helps reduce overfitting in some cases
- Assists with handling noisy or outlier-heavy data
Cons:
- Loss of information: Fine-grained differences are removed
- It may introduce bias if bin thresholds are not well-chosen
- It can hurt performance for models that prefer continuous input (like linear regression)
Best Practices for Discretization
Discretization, when done right, can significantly enhance model clarity and usability. Here are some best practices:
- Use domain knowledge to define meaningful bin boundaries.
- Visualize data before binning to understand distributions.
- Avoid too many bins, which may overfit the model or complicate interpretation.
- Test different techniques and evaluate model performance to choose the best method.
- Check the class balance in bins to avoid skewed datasets.
Tools and Libraries for Discretization

Most popular data science tools and libraries provide built-in functions for discretization. Some of these include:
- Pandas (Python): pd.cut() for equal-width and pd.qcut() for equal-frequency binning
- Scikit-learn: KBinsDiscretizer for various binning strategies
- R programming: cut() and other binning functions
- Weka: Offers supervised discretization as part of its preprocessing steps
These tools help automate and simplify the discretization process.
Conclusion
Discretization in machine learning is a simple yet powerful technique for transforming continuous data into understandable and usable categories. Whether applied through equal-width binning, frequency-based grouping, or more advanced methods like decision tree splits, discretization helps models learn better, especially when working with categorical algorithms or noisy datasets. It enhances interpretability, reduces noise, and supports various real-world use cases from healthcare to finance. While it may not be necessary for every model, knowing when and how to apply discretization is a valuable skill for every data scientist and machine learning engineer.